


Googlebot gets lost fast on big stores. It doesn’t need much help when your catalog has 2,000 pages, but it does when filters, variants, search pages, and app parameters turn that into millions of URL states.
If your top categories and fresh products are slow to index, you usually don’t have a content problem. You have a crawl budget problem inside your ecommerce architecture, templates, and release process. The fix in 2026 is simple to state and hard to manage: give bots better paths to money pages, and stop feeding them junk.
Start with a crawl map, not a blanket block
Pull 30 days of server logs and Search Console Crawl Stats before touching robots.txt. Then group Googlebot hits by template, parameter pattern, and business value.
On large catalogs, waste usually clusters around sort URLs, faceted combinations, internal search-result pages, thin variant URLs, and retired seasonal pages that never leave the sitemap. A practical 2026 workflow for large sites starts with this inventory, because you can’t fix what you haven’t classified.
Map each URL pattern into three buckets: pages Google should discover and refresh often, pages that support UX but don’t deserve indexation, and pages that should stop receiving crawl attention. This framing keeps teams from treating every non-canonical URL as a threat. Some are helpful. Many are noise.
This quick matrix works well during audits:
| URL pattern | Crawl | Index | Main risk |
|---|---|---|---|
| Core category pages | Yes | Yes | Weak internal links or JS-only discovery |
| Curated facet landing pages | Yes | Yes | Canonicalizing away pages with demand |
| Sort and tracking parameters | No | No | Crawlable HTML links across the site |
| Internal search pages | Rarely | No | Query URLs entering sitemaps |
| Variant URLs | It depends | It depends | Collapsing distinct sellable SKUs |
Compare crawl share with revenue share and indexation lag. If 30% of Googlebot hits land on filter combinations with no entrances, you have crawl leakage. If new products sit in “Discovered, currently not indexed” while bots revisit stale parameter pages, your priorities are upside down.
Be careful with pagination and seasonal inventory. Paginated category pages still help product discovery, especially when infinite scroll hides deeper listings. Meanwhile, seasonal URLs that return every year should usually stay live, not bounce through chains of redirects each off-season.
Fix filters, variants, and search pages with URL rules
Faceted navigation is where crawl budget ecommerce issues usually explode. The goal isn’t to kill filters. The goal is to keep shopper-friendly filtering while limiting bot access to low-value combinations.
Start with an allowlist. Index only category and facet pages that match real demand, such as a brand page, a gender split, or a curated “waterproof hiking boots” collection. Everything else, including sort orders, price sliders, session IDs, and most multi-select combinations, should stop generating crawlable paths. If you run Shopify, this Shopify faceted navigation SEO checklist is a solid model for documenting those rules.
If a filter changes search demand, treat it like a landing page. If it only rearranges the same products, keep it user-only.
Use robots.txt for patterns that never need crawling, such as endless sort parameters or internal search. Still, don’t rely on it as a de-index tool. Blocked URLs can remain indexed if Google finds them through links, and Google can’t see a noindex tag on a blocked page.
Use noindex when a page can still be crawled but shouldn’t stay indexed, such as internal search results or thin off-season pages. Use canonicals for near-duplicates that remain accessible to shoppers, such as a color parameter that doesn’t change intent. Yet canonicals are only hints. They work best when the pages are truly close matches.
Product variants need a harder look. A size selector rarely deserves a unique indexable URL. A variant with its own images, inventory, price, and search demand often does. Canonicalizing every child SKU to one parent can hide in-stock items and erase long-tail visibility. On Magento, layered navigation and duplicate category paths create the same problem at a larger scale.
Modern platform stacks add risk here. Merchandising apps, campaign links, and client-side routers can generate fresh parameter patterns overnight. That means crawl rules need ownership across SEO, engineering, and merchandising, not one cleanup ticket after launch.
Raise crawl demand for money pages
Once low-value paths are under control, make important URLs easier to find and refresh. That means cleaner taxonomy, better HTML links, tighter sitemaps, and faster templates.
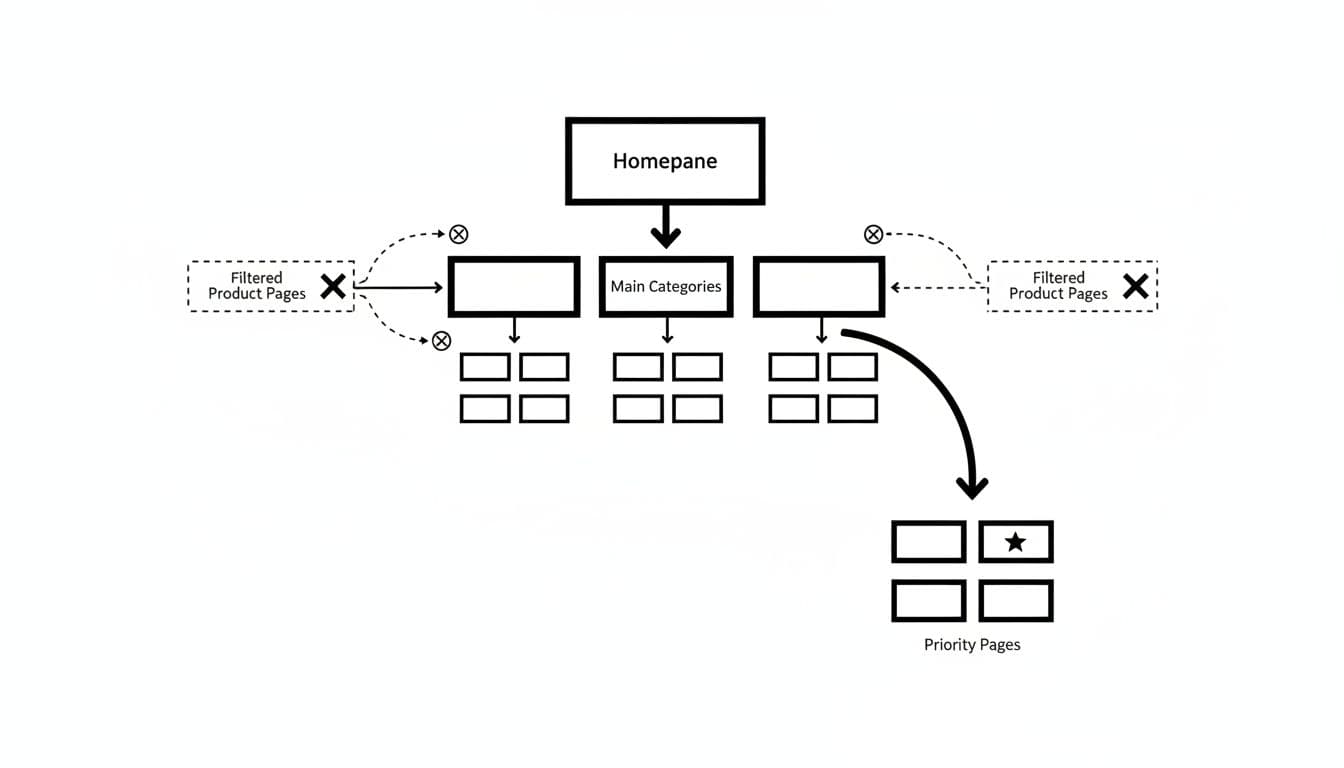
Keep top categories close to the homepage and linked in HTML. Then link subcategories to products, products back to collections, and guides into commercial pages. A stronger ecommerce internal linking strategy raises crawl demand because Google sees repeated, relevant paths to the URLs you care about.
Taxonomy matters more than many teams admit. If categories overlap or breadcrumbs reflect messy product assignment, crawl paths get diluted. Headless builds add another layer. If pagination, breadcrumbs, or product cards appear only after hydration, Google may discover less than your QA team sees. Core links should exist in the initial HTML.
Sitemaps still matter on large stores. Include only canonical, indexable, 200-status URLs, and use honest lastmod dates for real changes like stock, price, or copy updates. Don’t stuff sitemaps with redirected, blocked, or noindexed URLs. This crawl budget optimization guide for 2026 makes the same point: sitemap hygiene matters most when catalog size and change frequency are high.
Server response sets the ceiling. Slow category templates, bloated third-party scripts, and unstable inventory calls reduce crawl rate. That hurts shoppers first, and then it tells Google to back off.
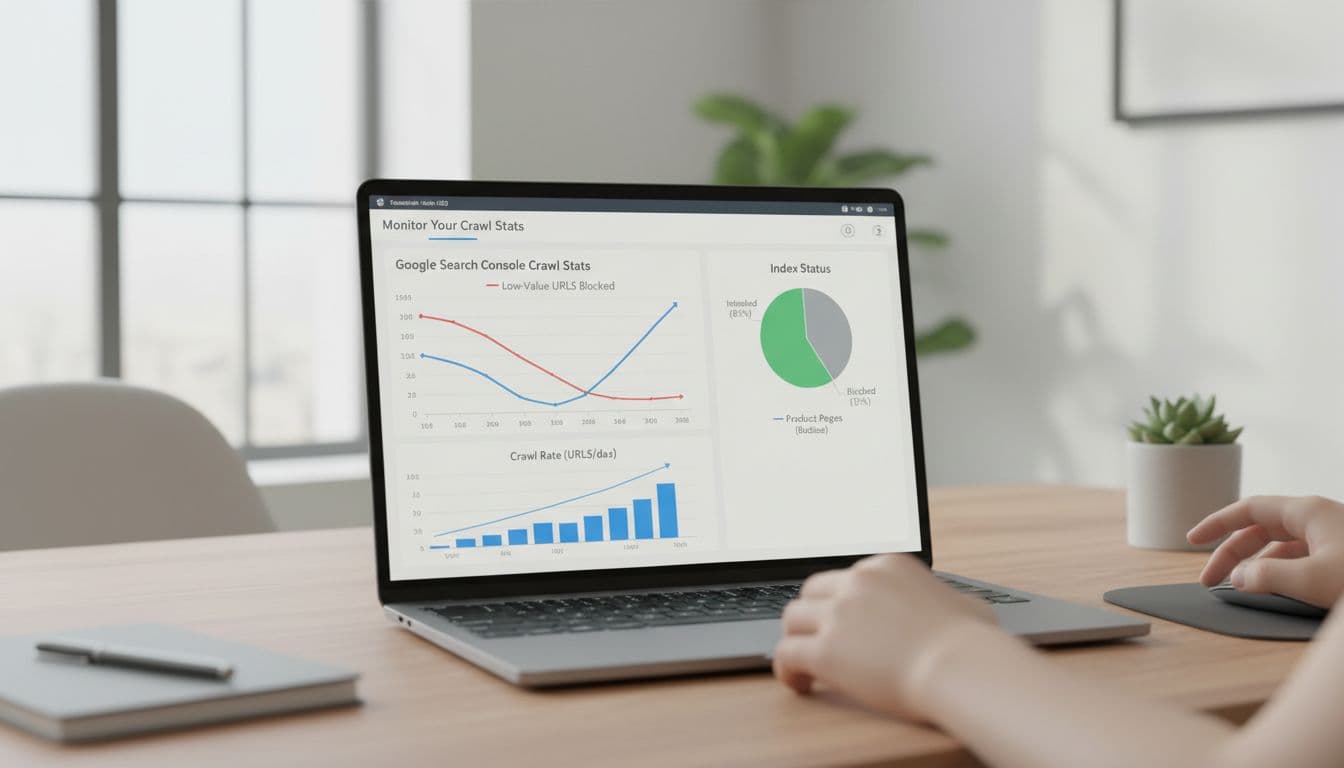
After each release, compare Crawl Stats, log files, indexed counts, and “Discovered, currently not indexed” by template. Treat new parameter patterns as defects. The best enterprise teams tie crawl checks to release gates, merchandising changes, and seasonal launches.
Conclusion
Large stores rarely need more pages crawled. They need better URL governance. When category pages, priority products, and carefully chosen facet landers are easy to reach, Google spends more time where revenue lives.
The safest fixes are selective. Block the junk, keep the money pages open, and review every new parameter source before it ships. On enterprise ecommerce sites, crawl efficiency is less about one perfect rule and more about holding the line after every release.



