


Headless commerce gives you flexibility, but search engines still need plain signals they can read fast. If the storefront waits on client-side scripts, crawlers can miss products, links, and pricing.
In 2026, strong headless ecommerce SEO depends on renderable HTML, clean API output, and tight performance control. That mix keeps visibility stable while your team ships faster.
Use this checklist to spot the weak points before they become lost traffic.
Start with a rendering model search engines can trust
The safest pattern is SSR for product and category templates, SSG for stable editorial pages, and ISR when you need fresh stock or pricing without rebuilding every page. A recent headless ecommerce SEO guide makes the same point, critical content should arrive in HTML, not wait for JavaScript.
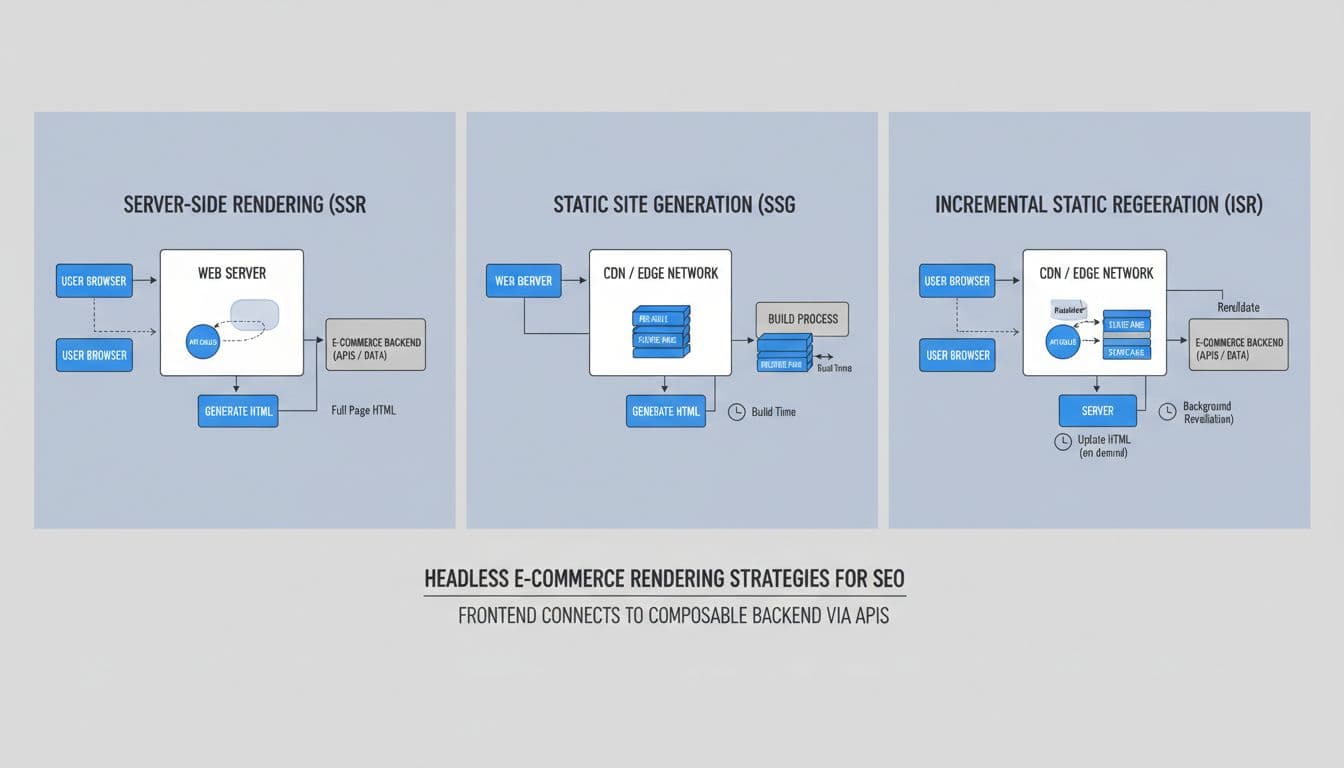
- Use SSR for money pages that change often, such as product detail pages and main category pages.
- Use SSG for content that rarely changes, like buying guides, size charts, and evergreen brand pages.
- Use ISR for pages that need fresh inventory, but not a full rebuild on every visit.
- Keep primary text, prices, and internal links in the first HTML response.
- Avoid client-side rendering for anything that carries the page’s main search intent.
If a critical page needs JavaScript to reveal basic copy, it is already at risk.
Make API-driven pages crawl cleanly
Headless stores live on APIs, but crawlers do not care how elegant the backend is. They care about what the page returns. If you’re moving platforms, preserving rankings in headless rebuilds depends on what the crawler receives, not what the design system can paint later.
- Expose product title, price, availability, breadcrumbs, and review summary in the server response.
- Render category links and pagination in HTML, not only inside app state.
- Keep filters crawl-safe. Block thin parameter combinations from indexing when they create duplicate pages.
- Return clean 404 or 410 responses for dead products, and point replacement SKUs to relevant alternatives.
- Keep top navigation and category paths visible to bots, even if the UI uses modern interaction patterns.
A good rule is simple. If a crawler needs to click, scroll, or wait for a fetch before it sees meaning, the setup needs work.
Keep Core Web Vitals under control
Speed matters more in headless setups because JavaScript can pile up fast. The goal is not just a fast homepage. It is fast product pages, fast categories, and fast mobile browsing across the whole catalog.

- Ship less JavaScript on product and category templates.
- Preload the main image and reserve space for banners, badges, and carousels.
- Push images, scripts, and CSS through a CDN close to your users.
- Cache HTML at the edge when the page does not change every minute.
- Use short cache windows for price, stock, and promo data.
- Move personalization and recommendation widgets off the critical path when possible.
A headless build can still feel slow if the front end carries too much weight.
Build metadata and sitemaps from source data
Metadata should come from the same system that powers the product page. Hand-edited tags break easily. Source-driven tags stay in sync with the catalog and save time during launches. For larger catalogs, headless CMS sitemap practices are a useful reference because they show how to generate XML feeds from live content, not static files.
- Generate canonical tags from the actual page type, not a template guess.
- Publish Product, BreadcrumbList, Organization, and Review schema only when the page data supports it.
- Keep hreflang, locale folders, and canonical URLs aligned across markets.
- Split large sitemaps by product type, region, or language.
- Update
lastmodwhen copy, stock, or availability changes.
Do not add schema that the page cannot prove. Search engines compare markup with on-page content, and mismatches can waste crawl trust.
Test the storefront like a crawler before every release
QA is where many headless SEO problems show up, but only if you test the right things. A beautiful UI can hide broken HTML, missing links, or a blank page for bots.
- Crawl staging with JavaScript turned off.
- Compare raw HTML with the rendered DOM on key templates.
- Check product, category, and content pages on mobile screens first.
- Test slow connections, not only office Wi-Fi.
- Verify analytics, consent tools, and tag managers do not block key content.
- Review logs, crawl stats, and index coverage after launch.
A release is not ready until the bot version and the shopper version both work.
Conclusion
Headless ecommerce SEO in 2026 is not a tag-fixing exercise. It is a build choice, a cache choice, and a testing choice.
When SSR, structured data, CDNs, and QA all point in the same direction, search engines can read the store without guesswork. That is the real advantage of headless, speed for shoppers, and clear signals for crawlers.



